.png)
.png)
.png)
Именно сложности в оформлении нетривиальных таблиц порождают вопросы читателей. Посмотрите на рис. 1 — оформить одними стилями, существующими в InDesign CS3, не получится. Подобных примеров можно привести множество. Но если к Магомету не идёт гора… К счастью, героических усилий не понадобится — достаточно вспомнить о расширенных возможностях по написанию и поддержке сценариев, заложенных в программу вёрстки.
Сначала дадим немного общей информации, а потом приведём полностью готовый скрипт, модифицировать который под собственные потребности с учётом изложенного материала вы сможете сами.
Чтобы воздействовать на объект в публикации, его надо сначала указать. В вёрстке это происходит выделением, в скриптинге — заданием пути к объекту. Путь формируется последовательным перечислением всех объектов, в состав которых входит данный. Поскольку все объекты публикации разбиты по типам (collection), также указывают порядковый номер необходимого элемента из коллекции. Например, для обращения к третьему текстовому фрейму на второй странице используют pages[1].textFrames[2] (счёт ведётся с первого элемента, имеющего нулевой порядковый номер). Pages — ссылка на коллекцию всех страниц, а textFrames — на все текстовые фреймы (в данном случае — принадлежащие только конкретной странице). Разумеется, страницы тоже не находятся в вакууме, а входят в состав определённой публикации, которая управляется приложением application (InDesign). Полный путь к фрейму таков:
myFrame = app.activeDocument.pages[1].textFrames[2].
Если пропустить ссылку на pages[1], программа начнёт считать фреймы в том порядке, в котором они создавались — без разделения по страницам, что будет некорректно, поскольку данный фрейм может иметь в публикации любой индекс — хоть 100000. Аналогичная ситуация возникает, если нам нужен фрейм на определённом слое или же входящий в состав другого фрейма. Следовательно, принципиальное значение для указания объекта воздействия имеет внутреннее устройство публикации (есть термин «объектная модель»), в которой чётко определено, как один объект может быть связан с другими.
Смысл понятия «объект» в скриптинге шире, нежели в привычной жизни, — под ним понимается абсолютно любой элемент публикации: образец цвета (swatch), набор параметров для печати (Print Options), стиль абзаца (paragraphStyle), линии (lineStyle) или же набор параметров для экспорта (exportOptions). Такая повальная «объектизация» позволяет составить чёткую иерархию элементов публикации.
В иерархии определены все допустимые месторасположения объектов: одни могут быть размещены в любом месте страницы (например, геометрические примитивы — овал, прямоугольник и т. п.), положение других зависит от положения третьих (например, текст может существовать только во фрейме). К последним относятся и таблицы — вставленные во фрейм, они ведут себя как обычные символы (точнее, как графика IN-LINE): перетекают вместе с текстом, выталкивают его и т. п. Таким образом, объектом более высокого уровня (или родителем) у таблицы является символ (Character), который входит в состав абзаца (Paragraph), в свою очередь входящего в материал (Story). Следовательно, чтобы обратиться к первой таблице в материале, можно написать myTable = myStory.tables[0], если же речь о таблице, находящейся в конкретном абзаце: myStory.myParagraph.tables[0].
Заметьте: как и в самом первом случае, мы использовали множественное число — tables, а не table, поскольку всегда сначала обращаются к интересующей коллекции, после чего в квадратных скобках указывают порядковый номер конкретного объекта. При этом tables[0] даёт ссылку на объект Table, что совершенно логично.
Создание таблицы ничем не отличается от создания какого-либо другого объекта публикации — используется универсальный метод add():
NewTable = myTextFrame.myInsertionPoint.tables.add(),
где myInsertionPoint — конкретное место в текстовом фрейме.
При создании таблицы можно сразу же задать количество строк и столбцов, при этом высота шапки (количество строк повторяющегося на других страницах заголовка) не учитывается и задаётся отдельно (headerRowCount).
Все параметры форматирования таблиц, извест-ные по работе с офисными пакетами, присутствуют в InDesign — вплоть до поддержки шапок и запрета разрыва строк при переносе между страницами. Поддерживает пакет и вложенные таблицы — содержимым ячеек которых могут быть другие таблицы.
Таблица состоит из набора строк (rows) и столбцов (columns), образующих на пересечении ячейки (cells). Они могут быть образованы слиянием нескольких ячеек (не важно — по горизонтали или вертикали), тогда говорят об объединённых ячейках.
Если нужно обратиться, например, к 3-й ячейке в 3-й колонке, достаточно написать myCell = myTable.columns[2].cells[2] — InDesign сначала перейдёт на необходимую колонку, где найдёт ячейку с соответствующим номером. Для удобства есть ещё один способ: через специальные слова firstItem(), lastItem(), everytItem() соответственно для самого первого, последнего и всех входящих в состав родителя объектов.
Оптимизация обработки множества ячеек
Поскольку часто множество элементов форматируется однотипно, в InDesign есть специальный механизм их пакетной обработки — метод itemByRange(). В отличие от решения «в лоб», когда по очереди применяется ряд свойств каждому элементу, здесь их присваивают одним махом для всего диапазона. А его можно задать любым способом, например, через:
-
объекты: itemByRange(cells[2], cells[99]),
-
спец. слова: itemByRange(firstItem(), lastItem()),
-
индексы: itemByRange(3, length-2).
В зависимости от того, к какому объекту метод itemByRange() применён, получают диапазон строк (если применён для строк), столбцов или ячеек. Для обращения ко всем ячейкам из первой колонки, за исключением начальной (рис. 2, зелёные ячейки), можно написать:
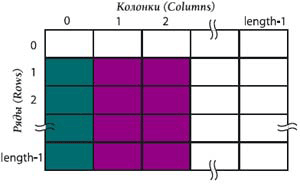
myTable.columns[0].itemByRange(myFirstCell, myLastCell)
где myFirstCell = myTable.columns[0].cells[1], myLastCell = myTable.columns[0].cells[myTable.columns[0].cells.length-1]
Свойство length — количество элементов заданного типа. Поскольку запись громоздка, лучше использовать укороченный вариант — через объект lastItem():
MyLastCell = myTable.columns[0].cells.lastItem()
Получим:
myRange = myTable.columns[0].itemByRange(myTable.columns[0].cells[1], myTable.columns[0].cells.lastItem())
С учётом возможностей JavaScript, в котором предусмотрен оператор with(), получаем сокращённую запись:
with(myTable.columns[0].cells)
myRange = itemByRange(1, lastItem())
Согласитесь, это гораздо читабельнее. Сначала задаём общий объект myTable.columns[0].cells, который является ссылкой на все ячейки из первого столбца, затем среди них задаём конкретный диапазон.
А вот случай посложнее. Ограничимся теми же ячейками, но только находящимися во 2-м и 3-м столбцах (рис. 2, фиолетовый цвет):
with(myTable.columns.itemByRange(1,2).cells)
myRange = itemByRange(1, lastItem())
Аналогично для строк:
with(myTable.rows.itemByRange(1,2).cells)
myRange = itemByRange(1, lastItem())
Так же решаются вопросы воздействия на любые участки — например, получаем ссылку на все ячейки таблицы за исключением самых крайних (рис. 3):
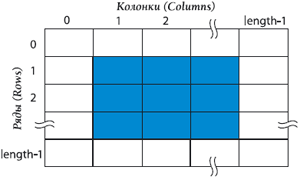
myRange = myTable.columns.itemByRange(1,length-2).cells.itemByRange(1,length-2);
Форматирование таблицы
Строки, столбцы и ячейки имеют аналогичные параметры: высоту (height), ширину (width), заливку (fillColor) и окантовку. Что касается последней, то каждая сторона, образующая ячейку, может иметь собственную ширину (strokeWeight), тип (stroke), цвет зазоров и т. п. Кроме того, ячейка имеет отступы от границ до содержимого (со всех сторон — topInset, bottomInset, leftInset, rightInset).
Ширина ячейки определяет ширину колонки, в которой она находится, высота — высоту строки, которой она принадлежит. Единственное исключение — когда несколько ячеек объединены по вертикали или горизонтали.
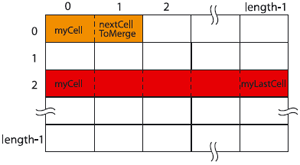
Для объединения ячеек служит метод merge(), воздействующий на диапазон, задаваемый первой и последней объединяемыми ячейками. Например:
myCell.merge(myCell, nextCellToMerge))
объединит две соседние ячейки; если надо объединить сразу несколько, вспомните метод itemByRange():
myCell.merge(cells.itemByRange(myCell, cells.lastItem()))
В приведённом примере происходит слияние всех ячеек между ячейкой myCell и последней.
При использовании методов itemByRange, lastItem и аналогичных нужно помнить, что они дают ссылки на объекты — поэтому, например, запись cells.lastItem()-1 приведёт к ошибке, поскольку вычесть из объекта число не получится. Вместо этого можно пользоваться индексами, тогда результат вычитания будет корректным:
myCell.merge(with(cells) itemByRange(myCellIndex, length-1)),
где myCellIndex — индекс начальной ячейки.
Мы рассмотрели внутреннее устройство таблиц, способы эффективного управления целыми блоками и форматирование. Осталось ещё два момента, непосредственно связанных с работой скрипта, — цвет и стили.
Форматирование содержимого
Цвет в публикации может иметь любую цветовую модель, но для нас интересен именно CMYK, где цвет проще всего задать так: сначала цветовое пространство, затем тип (стандартная триада/заказные цвета), цветовые компоненты и название.
myColor = app.documents[0].colors.add({ColorSpace:ColorSpace.cmyk, ColorModel:ColorModel.process, colorValue:[0,0,50,100], name:’My Color1’})
Любой цвет имеет оттенок (Tint) со значениями от 0 до 100. По умолчанию, любой вновь создаваемый цвет имеет Tint = 100%. Когда цвет создан, к нему можно обращаться двумя способами: по индексу и названию. В последнем случае присвоение цвета объекту имеет вид:
myObject.fillColor = «My Color»
Свойство texts[0] для доступа к тексту как таковому включает в себя полностью весь текст, без разделения на абзацы и более мелкие объекты. При необходимости обратиться, например, ко 2-му абзацу в определённой ячейке, можно использовать конструкцию mySecondParagraph = myCell.texts[0].paragraphs[1]
Содержимое заданного текстового объекта находится в его свойстве contents. Вот как выглядит скрипт, который заносит в ячейку текст, полностью заменяя всё её содержимое:
myCell.texts[0].contents = «Это новое содержимое всей ячейки»
Или, если нужно заменить только второй абзац:
myCell.texts[0].paragraphs[1].contents = «Это новое содержимое только второго абзаца»
Форматировать текст можно как на уровне отдельных символов, так и целых абзацев, используя как непосредственное перечисление свойств, так и возможности стилей. В первом случае:
myParagraph.fillColor = myColor;
myParagraph.fontSize = 18;//в пунктах
Если параметров много, имеет смысл задать их в виде стиля. С точки зрения InDesign, стиль — не что иное, как обычный объект,
хранящий пары «параметр—значение». И создаётся он, как любой новый объект:
myParagraphStyle = myDocument.paragraphStyles.add({name:”myParagraphStyle”, fillColor: myColor, fontSize: 18})
Если необходимый стиль в публикации есть, его можно использовать для форматирования:
myParagraph.applyStyle(myParagraphStyle)
Итак, всю информацию для написания скрипта, результат работы которого представлен на рисунке, мы имеем. Переходим к практике.
Взмах волшебной палочкой
Разобьём все операции по форматированию таблицы на шаги.
-
Работаем со строками и присваиваем им необходимые параметры форматирования.
-
Точно так же поступаем с колонками.
-
Присваиваем заливку обоим диапазонам ячеек (первой колонке и, отдельно, всем остальным).
-
Объединяем верхние и нижнюю строки таблицы.
-
Финальные штрихи.
Перед выполнением шагов небольшая подготовительная работа: определяем основные параметры таблицы: ширину, отступы текста от краёв ячейки, толщину окантовки у ячеек, цвет фона — их удобно размещать в самом начале скрипта (на случай внесения в них изменений). Задаём ссылки на основные используемые объекты — документ, саму таблицу и стили абзацев.
ParaStyleExist = true;
tableW = ”122 mm”;
Inset = ”1 mm”;
strokeW = ”0.4 pt”;
tableFillColor = ‘C=80 M=29 Y=0 K=0’;
myDocument = app.activeDocument;
myTable = myDocument.selection[0].parent.parent;
myParagraphStyles = myDocument.paragraphStyles, pSA = [];
Находимы стили абзацев, которыми будем пользоваться. Для этого по очереди просматриваем все стили публикации и, в случае нахождения искомого, запоминаем его порядковый номер, иначе — устанавливаем признак ошибки.
for (i=2; i< myParagraphStyles.length; i++){
n = myParagraphStyles[i].name;
switch(n){
case ‘Table Zagolovok’: pSA[n] = i; paraStyleExist=false; break;
case ‘Table Podzagolovok’:pSA[n] = i; paraStyleExist=false; break;
case ‘Table Shapka’: pSA[n] = i; paraStyleExist=false; break;
case ‘Table Text Bold’: pSA[n] = i; paraStyleExist=false; break;
case ‘Table Text’: pSA[n] = i; paraStyleExist=false; break;
case ‘Box Istochnik’: pSA[n] = i; paraStyleExist=false; break;
case ‘Table Text Bold Cond’:pSA[n] = i; paraStyleExist=false; break;
case ‘Table Text Cond’: pSA[n] = i; paraStyleExist=false;
}}
Выводим окно диалога — оно необходимо для форматирования таблицы двумя стилями:
MyDialog = app.dialogs.add();
myDialog.name = ”Форматирование таблицы”;
with(myDialog){
with(dialogColumns.add()){
with(dialogRows.add()){
staticTexts.add({staticLabel: ‘Тип таблицы: ‘});
tableType = dropdowns.add({stringList:[”Обычный текст”, ”Сжатый текст”], selectedIndex:0});
}}}
if(myDialog.show()){ tableType = (tableType.selectedIndex = 0) ? ”Normal” : ”Condensed”}
else exit();
myDialog.destroy();
Дальнейшие действия имеют смысл, только если все необходимые стили определены:
if(paraStyleExist = true) {
Скрипт должен работать, только если выделена вся таблица, т. е. выделение имеет тип Table:
if(myTable.constructor.name = ”Table”){
Все необходимые для корректной работы скрипта условия определены, переходим к активным действиям:
with(myTable) {
Задаём ширину таблицы
width = tableW;
затем идём по строкам: каждой задаём отступы, толщину и цвет окантовки, вертикальное выравнивание и высоту. Отступаем три строки сверху и одну снизу (рис. 1):
with(rows){
fillArea = itemByRange(3, length-2);
with(everyItem()){
topInset = Inset;
topEdgeStrokeWeight = strokeW;
topEdgeStrokeColor = ”White”;
verticalJustification = 1667591796;//по центру
height = 0;
}
Отдельно занимаемся 3-й строкой — ведь именно с неё таблица и начинается: задаём форматирование для находящегося в ней текста, присваиваем заливку, параметры нижней окантовки и минимальную высоту строки.
with(rows[2]){
cells.everyItem().texts[0].applyStyle(myParagraphStyles[pSA[‘Table Shapka’]], true);
fillColor = fc;bottomEdgeStrokeWeight = ”4 pt”;
bottomEdgeStrokeColor = ”White”;
if(height<6) height = ”6 mm”;
}
Аналогично поступаем с самой последней строкой:
with(lastItem()){
bottomEdgeStrokeColor = ”Black”;
bottomEdgeStrokeWeight = strokeW;
cells[0].texts[0].applyStyle(myParagraphStyles[pSA[‘Box Istochnik’]], true);
topEdgeStrokeColor = ”Black”;} }
Следующий шаг — форматирование столбцов: каждому присваиваем параметры окантовки и задаём отступ слева:
with(columns){
with(everyItem()){
leftInset = Inset;
leftEdgeStrokeWeight = strokeW;
leftEdgeStrokeColor = ”White”;
}
last = firstItem().cells.length-1;
col1Txt = itemByRange(1, length-1).
cells.itemByRange(2, last).texts[0];
with(firstItem().cells) col0Txt = itemByRange(3, length-2).texts[0];
Поскольку до этого мы присваивали окантовку только левой стороне, внешняя часть крайнего столбца осталась неохваченной. Исправляем ситуацию:
with(lastItem()){
rightEdgeStrokeColor = ”Black”;
rightEdgeStrokeWeight = strokeW;
}}
columns[0].leftEdgeStrokeColor = ”Black”;
}
Так как у нас бывают таблицы двух типов (со сжатым и обычным текстом), в зависимости от заданного пользователем варианта задействуем свои настройки. Для первого варианта:
if(tableType==”Normal”){
fillArea.fillColor = tableFillColor;
fillArea.fillTint = 15;
col0Txt.applyStyle(myParagraphStyles[pSA[‘Table Text Bold’]], true);
col1Txt.applyStyle(myParagraphStyles[pSA[‘Table Text’]], true);
И для второго:
}else {
fillArea.fillColor = ”Black”;
fillArea.fillTint = 10;
col0Txt.applyStyle(pS [pSA [‘Table Text Bold Cond’]], true);
col1Txt.applyStyle(pS [pSA [‘Table Text Cond’]], true);
}
Наконец, финальные шаги: объединение строк в верхних двух строках и задание необходимых стилей абзаца:
with(tbl.rows[1]){
cells[0].merge(cells.itemByRange(cells[0], cells.lastItem()));
cells[0].texts[0].applyStyle(myParagraphStyles[pSA[‘Table Podzagolovok’]], true);
bottomEdgeStrokeColor = ”Black”;
}
with(tbl.rows[0]){
cells[0].merge(cells.itemByRange(cells[0], cells.lastItem()));
cells[0].texts[0].applyStyle(myParagraphStyles[pSA[‘Table Zagolovok’]], true);
topEdgeStrokeColor = ”Black”;
bottomEdgeStrokeColor = ”Black”;
topEdgeStrokeWeight = strokeW;
bottomEdgeStrokeWeight = strokeW;
bottomInset = 0;
verticalJustification = 1651471469;
}
Если ранее были найдены ошибки, скрипт останавливается и выдаёт соответствующее предупреждение:
}
else{alert(«Курсор должен находиться в таблице»)}
}else{alert(«Некоторые стили абзацев отсутствуют»)}
Задача выполнена, удачи в освоении скриптинга!
Работаем с ячейкой
Доступ к ячейке осуществляется несколькими способами. Первый — в формате cells.name[row_index, column_index], где сначала идёт порядковый номер строки, к которой ячейка принадлежит, потом — столбец. Альтернатива — cells[cell_index], где cell_index — порядковый номер ячейки в данной таблице. Нумерация ячеек — построчная. Относительный вариант позволяет задать в качестве базового как определённый столбец columns[column_index].cells[cell_index_in_this_column], так и строку rows[row_index].cells[cell_index_in_this_row]. Разумеется, отсчёт ячеек ведётся исключительно в пределах выбранного столбца/строки.
Выбирают из соображений удобства: если работа на уровне строки, логично выбрать последний, иначе — первый.







/13269462/i_380.jpg)
/13269431/i_380.jpg)
/13269450/i_380.jpg)
/13269463/i_380.jpg)